 Como digo siempre aquí y en todas partes, las expresiones regulares son una de las herramientas más útiles que podemos aprender como programadores (y sin ser programadores). Les puedes sacar partido para casi cualquier cosa que se te ocurra que involucre cadenas de texto, y no sólo programando. El problema que tienen es que son muy "anglosajonas" (como casi todo en este mundillo) y hay cosas que no hacen bien por defecto si usas caracteres que no sean anglosajones.
Como digo siempre aquí y en todas partes, las expresiones regulares son una de las herramientas más útiles que podemos aprender como programadores (y sin ser programadores). Les puedes sacar partido para casi cualquier cosa que se te ocurra que involucre cadenas de texto, y no sólo programando. El problema que tienen es que son muy "anglosajonas" (como casi todo en este mundillo) y hay cosas que no hacen bien por defecto si usas caracteres que no sean anglosajones.
Por ejemplo, supón que estás haciendo la validación de un formulario de alta de usuarios, y requieres un nombre o unos apellidos que contengan únicamente letras. Podrías usar una expresión regular como la siguiente para validarlo:
const nombre = "Perico de los Palotes";
const reNombres = /^[a-z\s]+$/i;
console.log(nombre.match(reNombres));
La expresión regular (/^[a-z\s]+$/i) es muy sencilla ya que indica que nuestra cadena permite cualquier letra y espacios entre el inicio y el fin de la línea (al menos debe de haber una), y se comprueba sin fijarse en mayúsculas y minúsculas (la i del final). Como es un nombre propio no se permitirán, por ejemplo, números ni otros caracteres "extraños".
Obviamente esta expresión regular es demasiado simple para hacer este tipo de comprobación, pero sirve para lo que quiero ilustrar. Y que no te sorprenda de todos modos verla por ahí utilizada 😉
En el caso de que el usuario introduzca como su nombre "Perico de los Palotes", como en el ejemplo de arriba, veremos por consola ese nombre, ya que se producirá una coincidencia con nuestro patrón. Si introducimos un nombre no válido, como por ejemplo "C3PO", no se producirá la coincidencia debido a que tiene un número, por lo que no se validará. Hasta aquí perfecto.
Pero ¿qué pasa si uso como nombre "Pepe Pérez"?: pues que tampoco se encontrarán coincidencias ya que esa "é" con tilde no entra dentro del rango de caracteres indicado, que va de la "a" a la "z" y no considera por defecto caracteres con tilde ni otros signos ortográficos como la diéresis o la virgulilla que va encima de las eñes.
La forma más fácil de hacer pruebas de todo esto es utilizar un servicio como regex101.com, que te deja probarlas en tiempo real tanto cuando cambias la expresión regular como el contenido a coincidir. Será lo que yo use a partir de ahora mismo para las explicaciones.
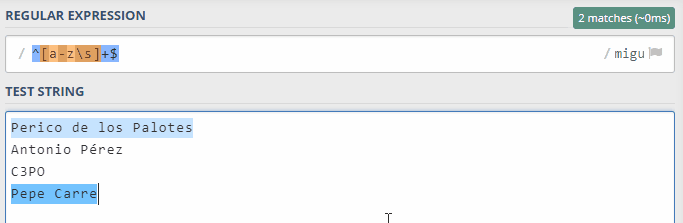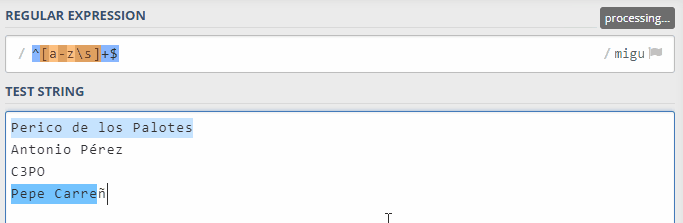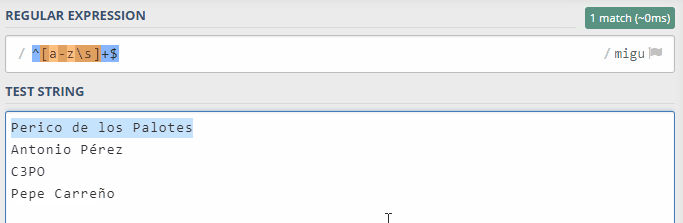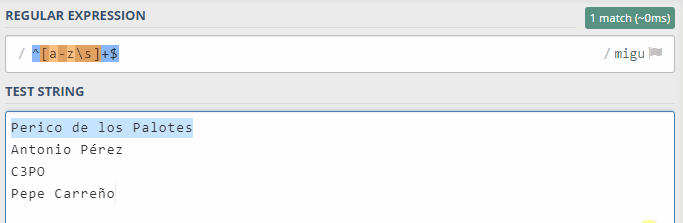
En esta pequeña animación puedes ver cómo tengo cuatro nombres para comprobar en regex101, y que el último de ellos empieza como coincidente, pero en cuanto escribo la "ñ" del apellido "Carreño", deja de ser coincidencia:
El flag /u para Unicode en ECMAScript 6
En junio de 2015 se lanzó la versión 6 de ECMAScript, cuyo nombre oficial es ECMAScript2015 y que fue la mayor revolución en el lenguaje desde hacía décadas, introduciendo muchísimas novedades que llevan el lenguaje a otro nivel. Entre todas esas novedades algunas menores pasaron inadvertidas para muchos. Una de ellas es esta: la posibilidad de especificar caracteres Unicode en las expresiones regulares gracias al flag /u
Los flags son esas letras que aparecen al final de las expresiones regulares y que sirven para indicar, por ejemplo, que la expresión no distingue entre mayúsculas y minúsculas (/i de case insensitive), que debe ser multilínea (/m) o global (/g) y que ya deberías conocer.
Pues en ES2015 hay varias nuevas entre las que se incluye /u, que sirve para hacer que se puedan especificar caracteres Unicode en la expresión regular. Estos caracteres se especifican mediante una expresión del tipo \u{xxxxx} en donde xxxx es el código hexadecimal que corresponde con el carácter Unicode que nos interese.
Por ejemplo, si quisiesemos una expresión regular para localizar todos los emojis como este: 😁 (que se llama oficialmente beaming face with smiling eyes), podríamos escribir la siguiente expresión regular:
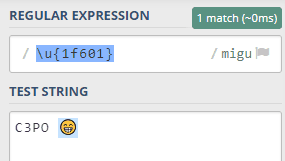
que lo único que contiene es el código Unicode de ese emoji en concreto (puedes verlos todos en la documentación oficial de Unicode). Fíjate en que lleva la /u al final (junto con otros flags que en este caso no vienen a cuento).
Ojo: si indicamos el flag /u en la expresión regular nos dará un error si usamos símbolos de escape con letras, como por ejemplo \u (por supuesto) o \a, \b, etc... Es decir, nos impide "escapear" letras, que por otro lado no tiene sentido hacerlo, pero bueno... Hay de todo por ahí, así que tenlo en cuenta. Esto es así para permitir otro tipo de secuencias de caracteres si fuese necesario.
Además de poder especificar caracteres concretos, el uso de /u permitirá que al usar un punto . en la expresión regular coincida cualquier carácter definido en Unicode excepto los terminadores. Por ejemplo:
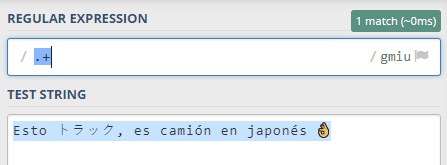
Pero no funcionará con expresiones como \w (para letras de una palabra, equivalente a [a-zA-Z0-9_]:
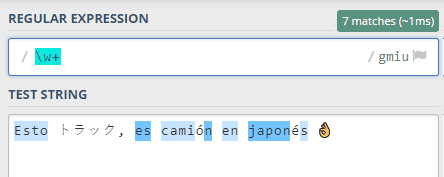
Fíjate en que NO está cogiendo las tildes, emojis ni símbolos en japonés. En otros lenguajes de programación como PHP, sin embargo, sí que funcionaría, pero no en JavaScript.
Es decir, aunque el flag /u fue un paso en la dirección adecuada, tenía muchas limitaciones para lo que nos importa en este caso.
Especificar propiedades Unicode en expresiones regulares
En el estándar Unicode cada carácter tiene propiedades asociadas, es decir, metadatos asociados a cada carácter. Estos metadatos/propiedades se utilizan para determinar la semántica de cada uno de ellos, ya que definen su identidad, normativa, propiedades y comportamiento. Entre estas propiedades están:
- Nombre (
Name): su nombre único, como por ejemplo "beaming face with smiling eyes" para el emoji 😁 que vimos antes.
- Categoría general (
General_category): por ejemplo, si es una letra en mayúscula (Uppercase_Letter) o minúscula (Lowercase_Letter), un número (Number) o un símbolo de entre varios tipos de símbolos (por ejemplo Currency_Symbol para monedas).
- Espacio en blanco (
White_Space): esta propiedad es booleana y es true o false en función de si el carácter es un espacio en blanco de algún tipo: un propio espacio en blanco, una tabulación o un retorno de carro, por ejemplo.
- Edad (
Age): que indica en qué versión e Unicode fue introducido. Por ejemplo para el símbolo del euro € esta propiedad vale 2.1 que fue la versión en la que se incluyó.
- Bloque (
Block): que indica a un bloque de caracteres contiguos, unos a continuación de los otros. un rango, vamos. Por ejemplo las letras del idioma inglés llevan Basic_Latin en esta propiedad, o los caracteres rusos tienen el valor Cyrillic (son caracteres en cirílico).
- Colección (
Script: que se refiere a una colección de caracteres concreta, generalmente asociados a un idioma, como Hebrew o Greek par letras en hebreo o en griego.
Existen más propiedades, pero estas son un buen ejemplo de las que hay y más nos interesan.
En JavaScript, a partir de ECMAScript 2018 es posible especificar conjuntos de caracteres Unicode a partir de sus propiedades, dando lugar a enormes posibilidades para localizar caracteres. Para lograrlo la sintaxis adecuada es:
\p{propiedad=valor}
o bien
\p{propiedad}
en el caso de propiedades booleanas.
Es decir, podemos localizar caracteres a partir de sus propiedades/metadatos, de manera muy sencilla.
Así, por ejemplo, para poder localizar cualquier letra de una frase, aunque sean palabras con tilde, eñes, o letras de otro idioma, podemos usar: \p{General_Category=Letter}, que nos dará aquellos caracteres de la cadena que tengan la propiedad General_Category con el valor Letter, que son aquellos caracteres considerados letras. De hecho, para hacer las expresiones más concisas y dado que la categoría general es algo que se utiliza muy a menudo, se permite indicar su valor directamente, sin necesidad de poner General_Category delante, simplemente así: \p{Letter}.
En nuestro ejemplo del principio podríamos usar tan solo la expresión regular \p{Letter}+ para lograr sacar todas las palabras de una frase, aún con letras en otros idiomas, como se puede ver en esta captura:
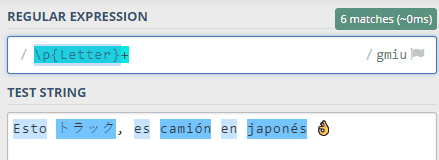
Por lo tanto, si quisiésemos validar un nombre, o sea, que solo tiene letras o espacios, y que funcione con tildes, diéresis, eñes, etc... nos llegaría con usar esta expresión regular: /^[\p{Letter}\s]+$/u
Del mismo modo podemos usar el código de escape con la "P" en mayúscula para lograr lo contrario, es decir, que se seleccionen los caracteres que no cumplan con esta condición:
\P{propiedad=valor}
o bien
\p{propiedad}
en el caso de propiedades booleanas.
Por lo que para sacar todos los caracteres que no sean letras usaríamos: \P{Letter}. Fíjate en que la "P" va en mayúsculas ahora.
Abreviaturas para mayor concisión
Existen abreviaturas para hacer la sintaxis todavía más concisa y más específica.
Por ejemplo, para las letras basta con poner \p{L} pero podríamos indicar también \p{Lu} para letras mayúsculas o \p{Ll} para letras minúsculas.
Es importante señalar que en este caso sólo se obtendrán letras que tengan su correspondiente contrapartida, es decir, si indicamos minúsculas, sólo las que tengan una versión en mayúscula. Por ejemplo, la letra ß en alemán (beta), solamente puede aparecer en el medio de una palabra por lo que no existe una variante en mayúsculas de la misma, así que \p{Ll} no la capturará porque aunque es una letra no se puede decir que sea mayúscula o minúscula. Así que mucho ojo.
Las abreviaturas más comunes que vas a utilizar son:
\p{L}: letras\p{Ll}: letras minúsculas\p{Lu}: letras mayúsculas\p{N}: números\p{Nl}: números que se representan como letras. Por ejemplo, los números romanos.\p{P}: símbolos de puntuación, como el punto, la coma, el punto y coma, los dos puntos, comillas...\p{M}: caracteres que se combinan con otros, como los acentos, el circunflejo, la diéresis...\p{Z}: separadores no visibles, como espacios, cambios de línea...\p{S}: símbolos matemáticos, de moneda, dingbats...\p{SM}: símbolos matemáticos\p{Sc}: símbolos de moneda
Extraer letras de idiomas concretos
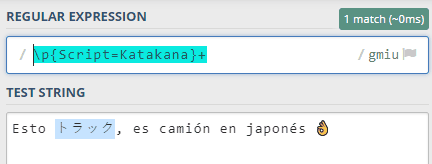
También, por ejemplo, para extraer todos los caracteres japoneses de una frase podemos usar la propiedad Script e indicar el nombre del alfabeto que nos interesa (en japonés hay 2: Hiragana y Katakana): \p{Script=Katakana}+:
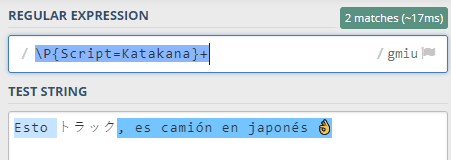
También, para extraer de nuestra frase todas las palabras que no tengan caracteres japoneses haríamos: \P{Script=Katakana}+. Fíjate que ahora la "P" está en mayúsculas, y fíjate en que se han seleccionado espacios, comas y el emoji ya que no son caracteres en japonés, claro:
Nota: la propiedad Script permite el uso de la abreviatura sc para ser más conciso. Por ejemplo \p{sc=Greek} para elegir una letra griega.
Expresión regular para obtener todos los emojis de una cadena de texto
Podemos obtener todos los emojis que hay en una cadena de texto usando la expresión regular: /\p{Emoji}/gu, ya que la propiedad Emoji es true para los emojis, pero por algún motivo también devuelve números entre 0 y 9, la almohadilla # y el asterisco *.
Así que, la forma de obtener tan solo los emojis de verdad sería más bien esta basándose en lo que indica el estándar:
/(\p{Emoji_Presentation}|\p{Extended_Pictographic})/gu
Pero por algún motivo no funciona en regex101.com, así que la tendrás que probar en tu navegador:

También puedes usar la abreviaturas \p{EPres} y \p{ExtPict}, soportadas por ECMAScript.
Esto puedes ser útil para librarte de los emoticonos allá donde no debas permitirlos, o para sustituirlos por gráficos propios si piensas que el sistema operativo del usuario quizá no los soporte.
Nota: si no usamos el modificador /u para la expresión regular, los emojis están considerados como dos caracteres ya que en realidad es así cómo se forman. Pero utilizando el modo Unicode (/u), los emojis y otros caracteres que usan doble código se consideran una sola letra.
En resumen
El manejo de caracteres Unicode es muy complejo porque el estándar Unicode es extremadamente complejo. Hasta ECMAScript2018 realmente no había una forma viable sencilla de gestionar los caracteres Unicode de manera grupal en expresiones regulares, y sólo se permitía el manejo de caracteres individuales usando el flag /u desde ECMAScript2015.
Por suerte en la actualidad es bastante sencillo manejar cadenas de caracteres complejas con expresiones regulares en JavaScript gracias a las propiedades Unicode de ES2018. En este artículo te he presentado las casuísticas más comunes para que aprendas a sacarles partido.
En este enlace del estándar tienes todas las variantes y abreviaturas soportadas por ECMAScript para manejar este tipo de caracteres desde expresiones regulares (deja que cargue completa para que se muestre la sección apropiada: es un documento muy grande).
¡Espero que te resulte útil!