Una de las cuestiones que más nos alucinaban cuando empezó toda la revolución informática en el hogar en los años '80 del siglo pasado eran los (en perspectiva) patéticos intentos que se hacían entonces para poder hacer hablar a los ordenadores. Que un chisme como mi Amstrad CPC 464 fuese capaz de balbucear con su voz metálica cualquier cosa que le escribiese en la línea de comandos era una gozada para cualquier adolescente de la época (si tenías uno de estos en casa, te gustaban esas cosas seguro). Lo malo es que la expectativas estaban muy altas desde que en 1982 apareció "el coche fantástico", Kitt (Knight Industries Two Thousand: el 2000 era el futuro lejano entonces, la máxima modernidad 😆), con su perfecta dicción y voz grave de sabelotodo.

Desde entonces y hasta hace relativamente poco, los avances en síntesis de voz han sido más bien "discretos", y las voces sonaban siempre metálicas y poco creíbles. Por no mencionar que tenemos asumido hace mucho tiempo que la inteligencia artificial dista mucho de hacer que un dispositivo hable y no es ni de lejos lo más complicado en todo esto.
No obstante, lo cierto es que hoy en día la síntesis de voz está completamente asumida y es tan común que hasta podemos conseguirla en nuestro navegador con unas pocas líneas de código.
Vamos a ver cómo...
La Web Speech API
Existe una completa API de habla en la Web cuyo estándar está todavía en borrador, pero que ya implementan hace tiempo todos los navegadores modernos (la excepción, como siempre, es Internet Explorer, pero no es moderno 😉). Esta API nos permite llevar a cabo las dos operaciones principales relacionadas con los mensajes hablados:
- Reconocimiento del habla, o sea, hablarle al ordenador y que entienda lo que dices y lo traduzca a un texto manejable por nuestro programa.
- Síntesis de voz, es decir, convertir en voz sintética un texto cualquiera que le escribamos.
Es de esto último de lo que me voy a encargar hoy, explicando cómo lograrlo con unas cuantas líneas de JavaScript y algunos detalles a tener en cuenta.
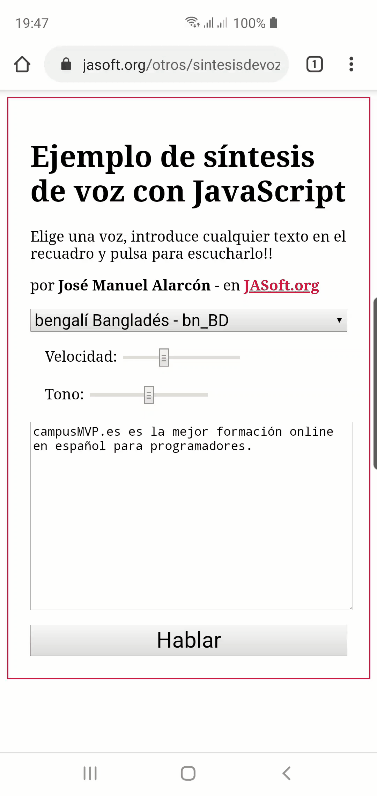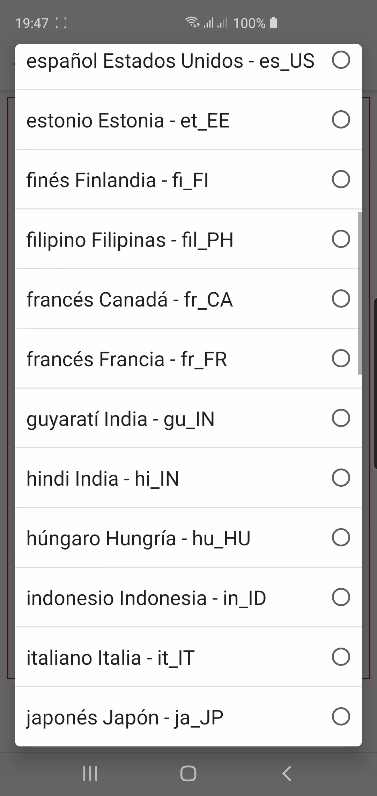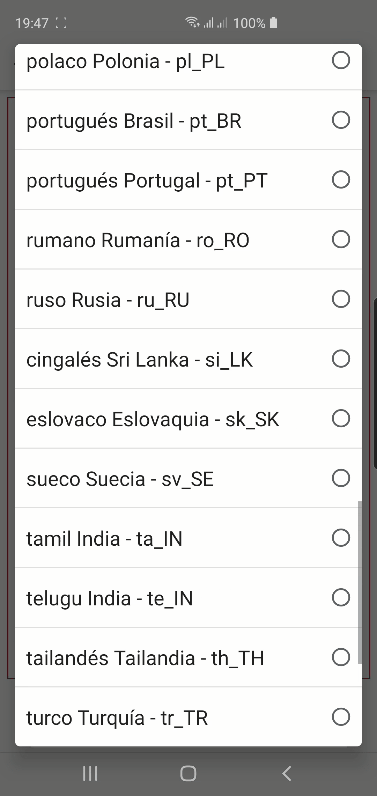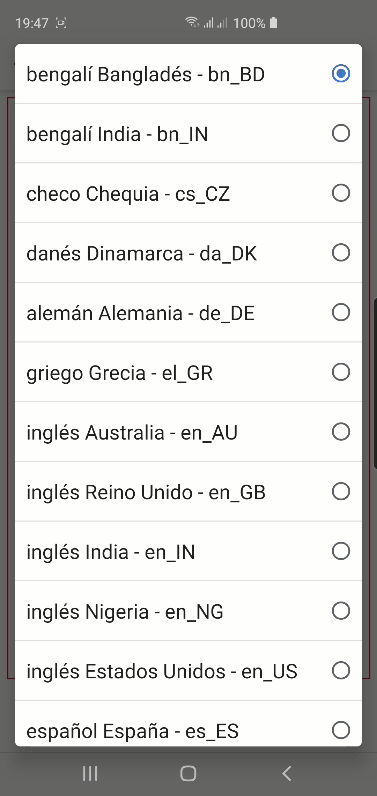
El ejemplo que he creado lo tienes aquí para que puedas probarlo.
Puedes elegir cualquier voz de las disponibles en tu sistema, cambiar la velocidad de habla y el tono, y pronunciará cualquier cosa que haya escrita en el cuadro de texto, incluyendo los emojis (que los describirá en voz alta).
Vamos a ver cómo está hecho.
Sintetizador, voces y declaraciones
Para poder acceder a la API de síntesis de voz debemos hacer uso de una propiedad del objeto global, en este caso, window, llamada speechSynthesis. Se trata de un objeto que implementa la interfaz SpeechSynthesis definida en el estándar y que define cómo se comporta un objeto sintetizador de voz.
Dispone de diversos métodos, propiedades y eventos, a saber:
Propiedades de SpeechSynthesis
speaking: devuelve true si se está generando voz a partir de texto en este momento.paused: nos dice si la síntesis de voz está pausada (true) o no (false).pending: devuelve true si hay declaraciones (ahora veremos qué son) en la cola, pendientes de sintetizarse.
Métodos de SpeechSynthesis
speak: sintetiza una declaración, generando la voz correspondiente.pause: detiene temporalmente la voz sintética que esté en marcha.resume: reanuda la síntesis de voz previamente pausada.cancel: cancela el habla y además elimina cualquier declaración que haya todavía en cola para ser sintetizada.getVoices: obtiene (no siempre, ahora lo veremos) una lista de todas las voces disponibles en el sistema para sintetizar el habla.
Eventos de SpeechSynthesis
voiceschanged: este evento se notifica cuando cambie la relación de voces disponibles para sintetizar el habla. Por ejemplo cuando añadimos una voz nueva al sistema, pero en realidad el evento es muy necesario para el uso común de la API, como veremos en un segundo.
A pesar de lo que diga la MDN, este evento no funciona ni está soportado en iOS ni en Safari para Mac, lamentablemente. Más sobre esto luego.
Pero los sintetizadores de voz no funcionan ellos solos en el vacío. Para poder trabajar necesitan combinarse con una voz concreta, que es la que le proporciona la pronunciación adecuada además de las reglas propias de cada lenguaje y sus variantes (por ejemplo, acento español de España o de Hispanoamérica, o que en inglés "tomato" se pronuncie diferente en EEUU que en Reino Unido).
Las voces se representan a través de objetos de tipo SpeechSynthesisVoice que poseen varias propiedades para definirlas:
name: es el nombre descriptivo de la voz, para que los humanos podemos reconocerla de manera sencilla. Por ejemplo Microsoft Helena Desktop - Spanish (Spain) o Google español de Estados Unidos. Existe una propiedad alternativa llamada voiceURI que ofrece un nombre único y que suele coincidir con el anterior, pero que puede contener también la dirección única del servicio de voz ue estemos utilizando.lang: el código BCP 47 del lenguaje al que se asocia la voz, por ejemplo es-ES para español de España o en-US para inglés de EEUU.
Importante: por algún motivo que desconozco, aunque el estándar dice que debe ser un código BCP 47 y por tanto utilizar un guión medio para separar el idioma de su variant (como acabamos de ver), en los móviles se utiliza el guión bajo como separador, o sea, por ejemplo es_ES o en_US. Hay que tenerlo en cuenta si queremos utilizar esta propiedad para, por ejemplo, filtrar las voces disponibles y elegir sólo las de cierto idioma y variante. Así que tenlo en cuenta.
default: devuelve true si la voz actual es la voz por defecto definida por el sistema operativo. Hay que tener mucho cuidado porque en algunos dispositivos móviles puede ser casi cualquier cosa (por ejemplo en mi móvil me pone como voz predeterminada el indio bengalí, básicamente por que es el primero de los disponibles, aunque yo tenga el español y el inglés como idiomas predeterminados para voz en el sistema).localservice: este es interesante porque nos indica si la voz actual está instalada en el sistema (true) o se va a utilizar un servicio remoto (en la nube) para hacer la síntesis de voz con ella. Nos puede ser útil sobre todo en móviles para, por ejemplo, mostrar solo voces locales y no consumir ancho de banda o no enviar posible contenido sensible a la nube de nadie (Google o Apple, vamos).
Bien, ahora que ya tenemos el sintetizador de voz y la voz que queremos usar todavía nos falta un pieza: las declaraciones, es decir las frases de texto que queremos convertir a voz. Lo que va a decir nuestra aplicación, vamos.
Estas declaraciones se definen a través de objetos cn la interfaz SpeechSynthesisUtterance que define propiedades y eventos para permitirnos declarar el contenido que queremos sintetizar y la manera concreta de hacerlo (con qué voz, qué velocidad, etc...).
Esta interfaz define varias propiedades para controlar su comportamiento:
text: es el contenido textual que queremos convertir a voz. Es la declaración en sí misma.voice: se le asigna el objeto de voz (SpeechSynthesisVoice) que queremos utilizar y que por tanto va a determinar cómo se pronuncia y se entona la declaración.lang: el idioma en el que está escrita la declaración. En realidad no debería ser necesario establecer esto nunca ya que debe coincidir con el idioma definido para la voz. Y en el escritorio no es necesario. Sin embargo en los dispositivos móviles debemos establecerlo o no funcionará correctamente, utilizando siempre el idioma por defecto que esté definido en el sistema. Por eso, conviene ajustarlo siempre.rate: la velocidad de reproducción, que puede ir entre 0.1 (parecerá una voz borracha) hasta 10 (no entenderás nada). El valor por defecto es 1.pitch: el tono de la voz, que va desde 0 (el más grave) hasta 2 (el más agudo). En algunas voces no funciona (o al menos yo no lo aprecio).volume: el volumen de la voz sintetizada que va desde 0 (no se oirá) a 1 (la más alta), siendo el volumen por defecto 0.5.
Ahora todo junto...
Vale, ya está bien de teoría. Ahora ya conocemos las tres piezas necesarias y sus propiedades, así que vamos a verlas en marcha. Puedes ver el código del ejemplo anterior pulsando con el botón derecho en el enlace del ejemplo del principio y viendo su código fuente (lo he metido todo en un solo archivo para facilitarlo).
Lo primero que hay que hacer es determinar qué voces están disponibles para sintetizar el texto, lo cual se consigue con el método getVoices() del sintetizador. Es decir, en teoría sería algo así:
let sintetizador = window.speechSynthesis;
let voces = sintetizador.getVoices();
Sólo hay un problema: no te funcionará.
El motivo es que getVoices tiene dos particularidades importantes:
- Es asíncrono.
- Es de ejecución "perezosa"
Esto quiere decir que cuando hacemos la llamada al método se devuelve el control al script inmediatamente y no devuelve nada. Además carga las voces en segundo plano sólo cuando llamamos al método por primera vez, por lo que tendríamos que llamarlo una segunda vez para poder obtenerlas.
Por ello, para poder obtener una matriz con todas las voces disponibles, en realidad debemos responder al evento voiceschanged que vimos antes. Éste saltará en cuanto la lista esté disponible, así que podemos gestionarlo para llamar de nuevo al método y obtenerlas, algo así:
let sintetizador = window.speechSynthesis;
sintetizador.addEventListener('voiceschanged', function() {
//Obtenemos la lista de voces
voces = sintetizador.getVoices();
if (voces.length > 0) {
//Procesamos las voces
}
}
});
sintetizador.getVoices();
Añadimos una función para gestionar el evento de que cambie la lista de voces disponibles. Dentro de éste obtenemos la lista llamando a getVoices. Fíjate en cómo llamamos a getVoices al final del bloque de código, pero sin recogerlas ni hacer nada con ellas. Esto se hace para provocar el refresco de la lista de voces disponibles (inicialmente vacía, recuerda que es carga "perezosa") y poder detectar el cambio (la nueva lista ya rellenada) en el evento anterior.
Nota: esto último en realidad no es necesario en los navegadores de escritorio puesto que en cuanto se accede a la propiedad speechSynthesis de la ventana se provoca la carga de la lista de voces. Sin embargo en navegadores móviles es indispensable hacer esta llamada o no se cargarán nunca. Por ello, y porque no hace daño nunca, lo recomendable es poner esta llamada "tonta".
El código anterior funcionará pero tiene un problema: en algunos navegadores al lanzar la síntesis de voz se vuelve a notificar el evento voiceschanged. Esto provocará que tu lista de lenguajes disponibles crezca a lo loco si la muestras en la interfaz de usuario (como hago yo en el ejemplo con la lista desplegable para elegirlas). Para evitarlo vamos a controlar si ya se han cargado previamente evitando estar procesándolas a cada rato. Al fin y al cabo no habrá cambios casi nunca y si los hubiera con refrescar la página completa ya estaría.
Mi código final para rellenar el desplegable con las voces disponible es este:
let sintetizador = window.speechSynthesis;
let voces;
let listaVocesCargada = false;
sintetizador.addEventListener('voiceschanged', function() {
if (!listaVocesCargada) {
//Obtenemos la lista de voces
voces = sintetizador.getVoices();
if (voces.length > 0) {
//Las añadimos al selector
voces.forEach( v => {
let optVoz = document.createElement('option');
optVoz.textContent = `${v.name} - ${v.lang}`;
if (v.default) optVoz.selected = true;
optVoz.setAttribute('data-voz', v.name);
selVoces.appendChild(optVoz);
});
listaVocesCargada = true;
}
}
});
sintetizador.getVoices();
Dejo la lista rellenada de elementos que representan la voz, seleccionado automáticamente la voz que está declarada como voz por defecto (que ya digo que en móviles no suele ser la adecuada en mi experiencia) y demás guardo su nombre en un atributo de datos (data-voz) de HTML5 para luego poder saber qué voz exactamente se ha elegido.
Obviamente tú podrías hacer algo más complejo, como por ejemplo filtrar para que sólo se ofrezcan voces en un idioma determinado, o solo voces ue se sinteticen localmente, etc... Sería muy sencillo usando las propiedades que hemos visto para el objeto SpeechSynthesisVoice.
IMPORTANTE: en Safari para macOS y en todos los navegadores en iOS (iPhone, iPad) lo anterior no funcionará. El motivo es que el objeto speechSynthesis no soporta el evento voiceschanged y las carga síncronamente. Por ello, para que funciones también en estos dispositivos es necesario llamar a la función de rellenado de la lista al menos una vez a mano, y es lo que he hecho yo en el ejemplo que tienes para descarga más arriba. Extraigo el manejador para que no sea una función anónima, y lo llamo acto seguido en lugar de llamar a getVoices(). Con esto funcionará igual en todas partes. Una pena que Apple no siga el estándar para esto.
Según el navegador y el sistema operativo la lista puede cambiar un montón.
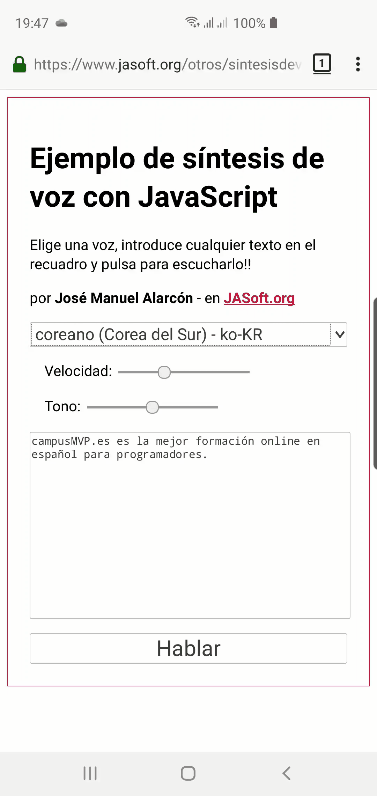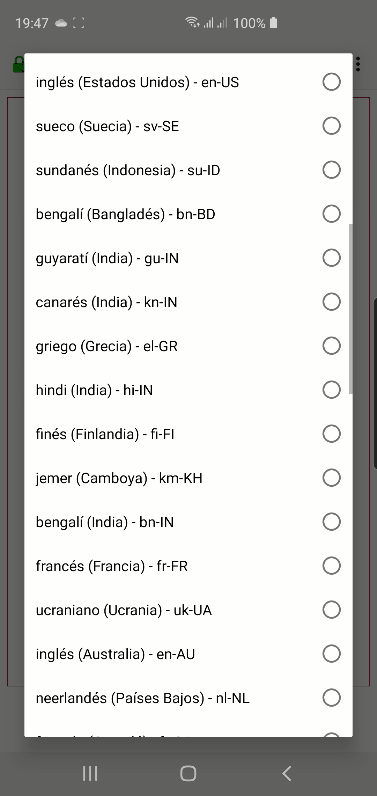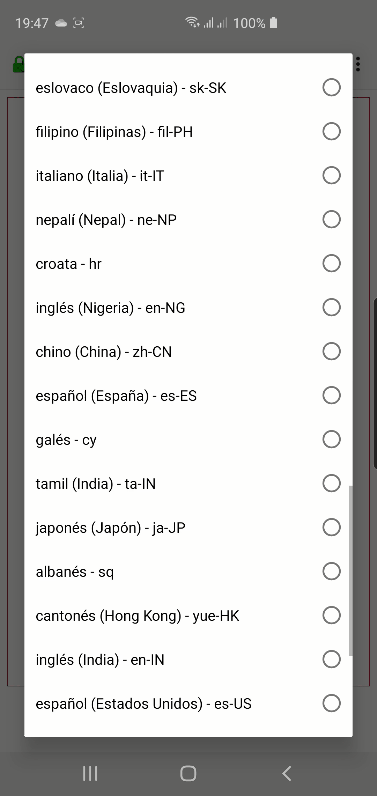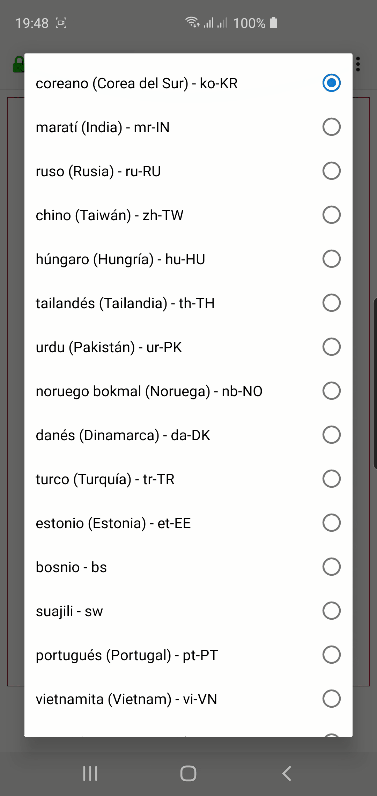
Esto es lo que se ve en mi equipo con Chrome bajo Windows:
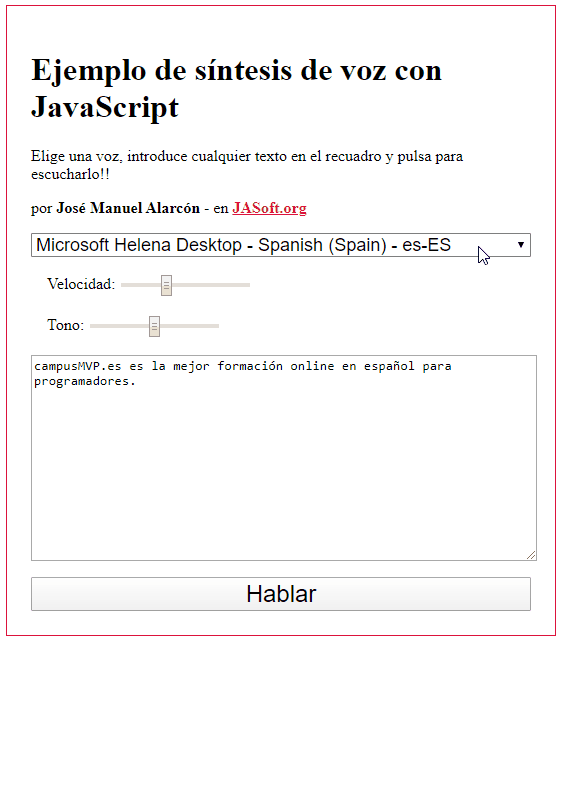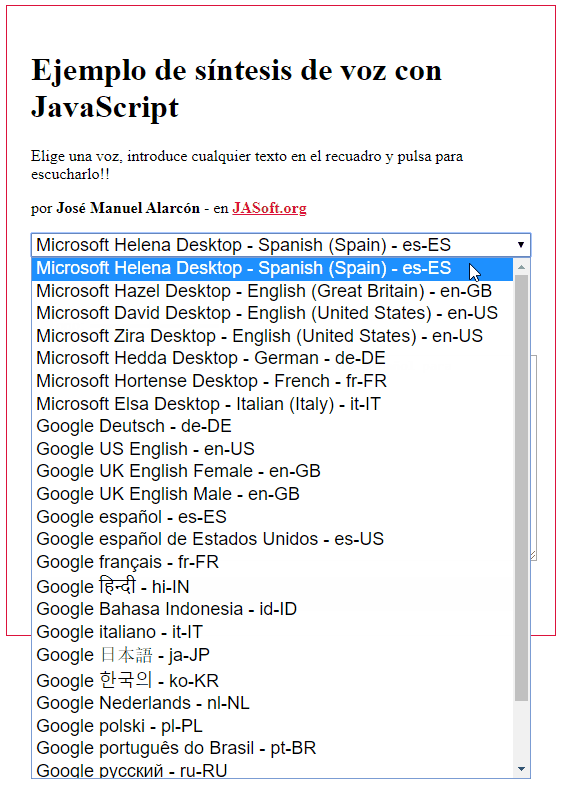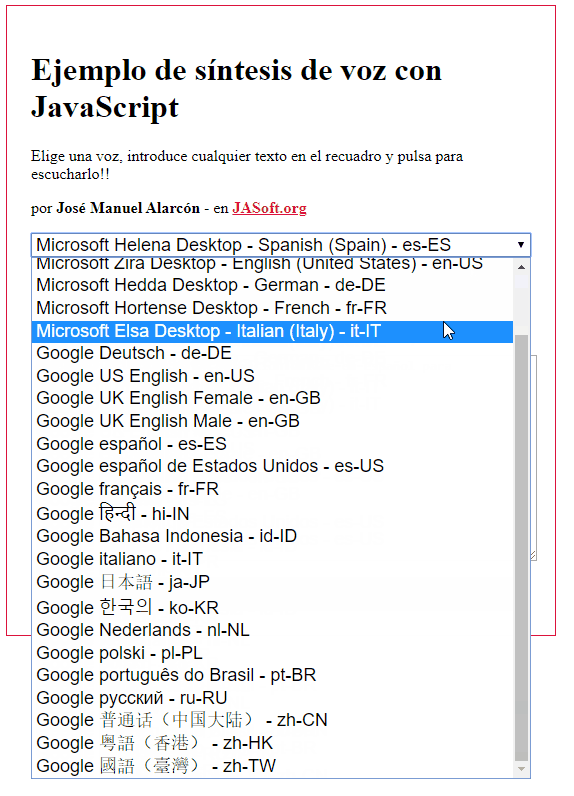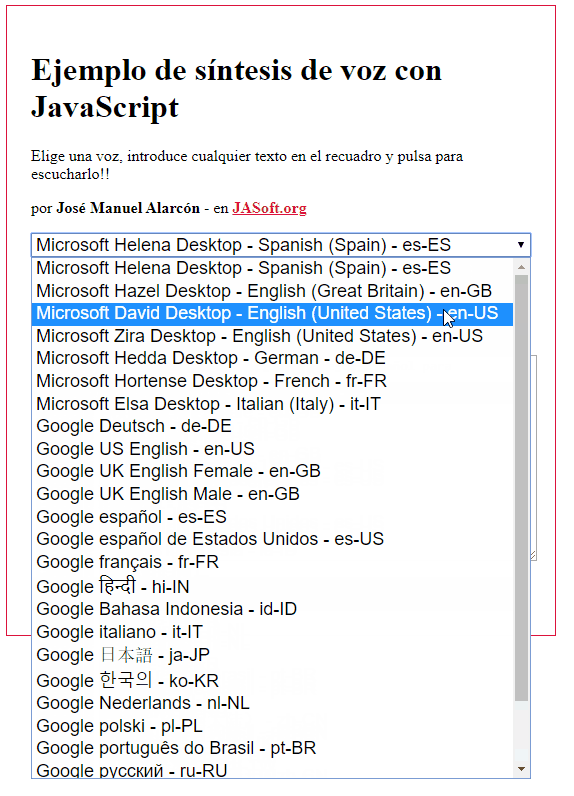
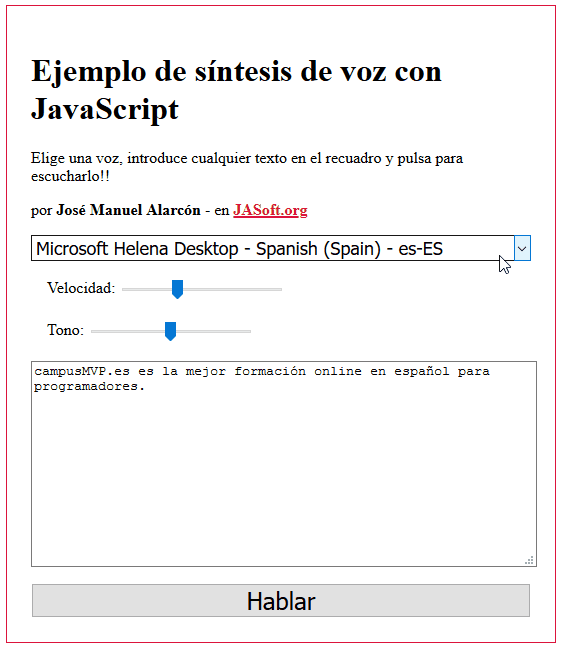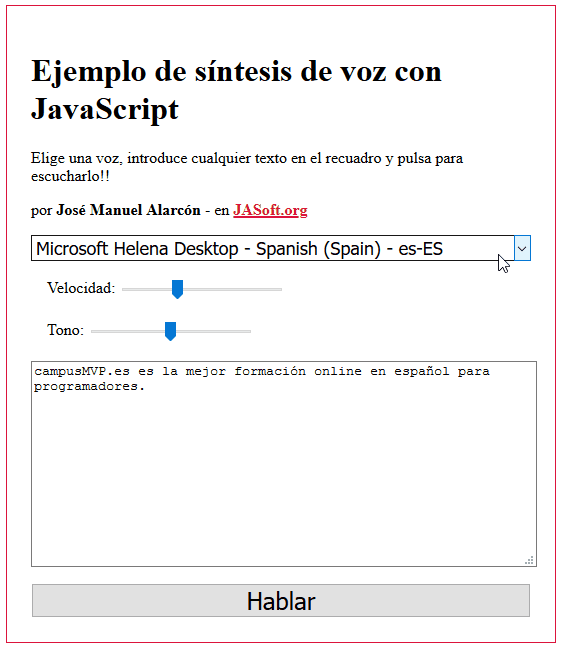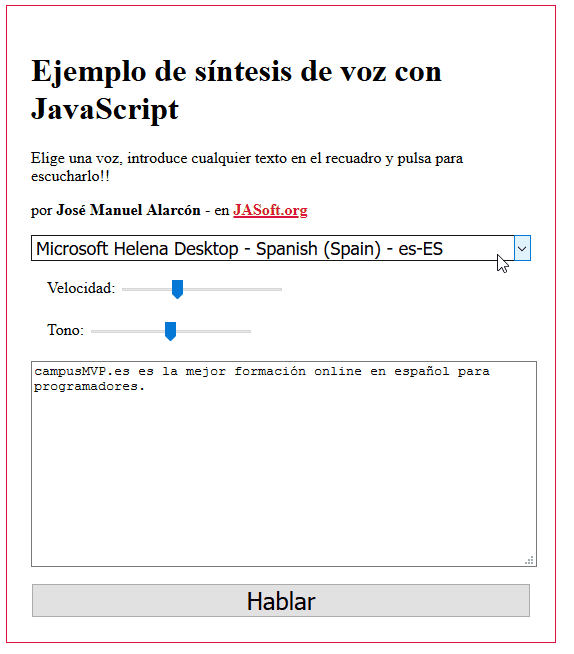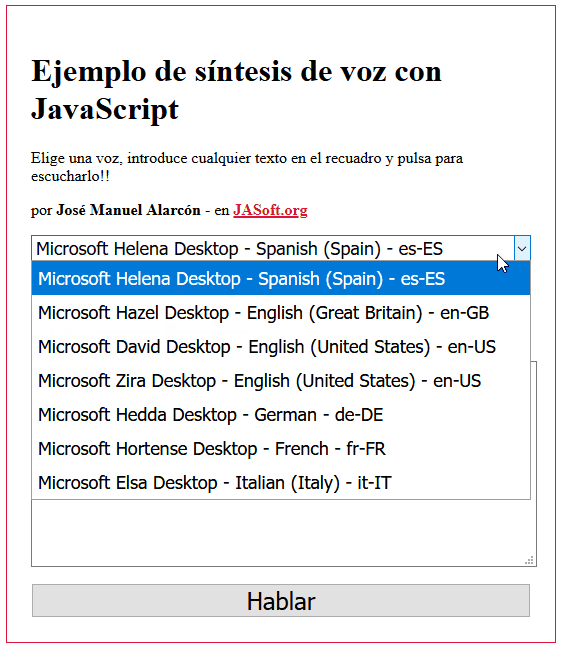
Como ves un montón. Sin embargo, en Firefox, las opciones son muchas menos por defecto, ya que saca solo las del sistema (Chrome ofrece también sus propios sintetizadores):
Curiosamente en Android hay muchísimas más opciones pero son diferentes en Chrome:
y en Firefox:
Y en otros navegadores, si utilizan Chrome por debajo (Brave, Edge...) se verá lo mismo que en Chrome, claro, y si usan su propio motor como Opera o UC Browser... pues mala suerte: no funcionará.
Vale, una vez que tenemos la lista de voces disponibles y el usuario ha elegido una, ponerla en funcionamiento es muy sencillo. Basta con crear un nuevo objeto SpeechSynthesisUtterance que ya hemos visto, y establecerle las propiedades que nos interesen:
//Creamos un objeto para la declaración
let declaracion = new SpeechSynthesisUtterance(txt);
//Asignamos la voz elegida
declaracion.voice = getVozElegida();
declaracion.lang = declaracion.voice.lang; //Necesario en móviles
declaracion.rate = velocidad.value;
declaracion.pitch = tono.value;
sintetizador.speak(declaracion);
En este caso averiguo cuál es la voz elegida a través del atributo data-voz que acabamos de ver, le establezco el lenguaje que tiene dicha voz (recuerda: es necesario para móviles, aunque redundante), y le asigno la velocidad y el tono que haya elegido el usuario.
Finalmente llamo al método speak para lanzar la declaración usando la voz sintética que le hemos asignado. ¡Listo!
Adicionalmente he gestionado algunos de los eventos disponibles para las declaraciones (en concreto start, end y error) para poder ir informando de lo que ocurre y para cambiar elementos en la interfaz. Por ejemplo, cuando se empieza a sintetizar la declaración cambio el botón de Hablar a Parar para permitir que se pare la síntesis de voz (aunque podría haberla simplemente pausado). Y también uso por ejemplo la propiedad speaking del sintetizador de voz para saber si hay una locución en marcha si se pulsa el botón, pudiendo distinguir entre si debo parar la voz o iniciarla. Cosas de fontanería...
Con todo lo que te he explicado en este artículo y el código de ejemplo puedes poner en marcha y adaptar la síntesis de voz en el navegador para tus necesidades sin dificultad.
¡Espero que te resulte útil!