 Una necesidad muy habitual en todo tipo de desarrollos Web es la de poder exportar información que tenemos en la página a archivos descargables que el usuario pueda utilizar.
Una necesidad muy habitual en todo tipo de desarrollos Web es la de poder exportar información que tenemos en la página a archivos descargables que el usuario pueda utilizar.
Para solucionar este problema, muchas veces se recurre a que, cuando el usuario pulsa el botón de exportar, lanzamos una nueva petición al servidor, y el documento descargable se genera al vuelo en el backend, siendo devuelto al usuario a través de Internet.
Esto está bien y de hecho es indispensable a veces, según el tipo de información y el formato del archivo que nos interese. Sin embargo, lo que muchos programadores Front-End no saben, es que es posible generar archivos para descarga directamente desde el navegador, usando tan solo JavaScript.
Y eso precisamente es lo que voy a explicar hoy en este artículo... Los formatos que voy a usar son sencillos (Excel, Word, CSV y HTML) pero nos vale para ver cómo se lleva a cabo esta técnica. Más adelante comento más sobre otros formatos y las "pegas" de estos.
El protocolo "data:"
Los navegadores modernos soportan un tipo especial de URI (identificador único de recurso) de tipo data: que nos permite definir los datos exactos que queremos visualizar de manera directa. Así, por ejemplo, es frecuente encontrar este tipo de URL con imágenes que van embebidas en los documentos, en lugar de descargadas de manera independiente. Pero también se puede utilizar para simular la descarga de otro tipo de archivos. Esto es lo que vamos a hacer para el caso que nos ocupa.
Lo primero que debe aparecer tras el prefijo data: es el tipo MIME del archivo que vamos a querer descargar, seguido de la codificación del mismo en caso de ser necesaria.
Estos son algunos de estos tipos MIME puestos a continuación de data: para algunos tipos de archivo:
- .html:
data:text/html
- .doc:
data:application/vnd.ms-word
- .csv:
data:text/plain
- .xls:
data:application/vnd.ms-excel;base64
En el caso de Excel, además, hay que codificar el resultado en Base64 para que la pueda interpretar adecuadamente, por eso lleva la codificación indicada al final. El resto son en texto plano.
A continuación se le pone una coma (,) y se coloca la información que va a ir dentro del archivo. Esta información debe ir codificada como Base64 o bien como texto plano, pero en este último caso debe ir adecuadamente codificada para formar parte de un URL, es decir, no vale escribir <h1>Hola Mundo</h1> como contenido, sino que deberá ir escrito como %3Ch1%3EHola%2C%20Mundo%3C%2Fh1%3E
Si te interesa, aquí tienes un Codificador/Decodificador en formato URL. Todos los lenguajes de programación de servidor tienen un par de métodos para hacer esto, y en JavaScript esto se consigue con el método encodeURIComponent.
Así, por ejemplo, un URI de este tipo válido sería:
data:text/html,%3Ch1%3EHola%2C%20Mundo%3C%2Fh1%3E
que si lo copias y lo pegas en la barra de direcciones de tu navegador descargará un archivo HTML con la cabecera "Hola mundo" escrita.
Hay que tener cuidado porque este tipo de URL puede que tenga limitaciones de tamaño máximo según el navegador. En las pruebas que he hecho se pueden crear documentos muy grandes sin problema, pero eso no quita que puedas crear uno tan grande que el navegador lo rechace o lo trunque, así que siempre debes tenerlo en cuenta.
La especificación completa de este tipo de URIs se puede leer en el IETF en el documento The "data" URL scheme, si te interesa conocerla a fondo, y data nada menos que de 1998, ¡hace casi 20 años!.
En el caso de archivos Excel podemos simplemente mandar el HTML de una tabla y Excel sabrá cómo interpretarlo, aunque no es lo más ideal.
Queda mucho mejor si rodeamos los datos tabulares con un HTML especial que Excel sabe interpretar y que permite indentificar más claramente a la tabla y además asignarle un nombre a la hoja correspondiente.
La constante es muy larga, no la voy a poner aquí, pero la tienes en el código fuente que he creado (ver más abajo).
Base64
Para algunos archivos, como los de Excel, es necesario codificar en Base64 los datos antes de generar el URI correspondiente.
Esto en JavaScript, por suerte, es muy fácil de conseguir.gracias a la función btoa del ámbito global (vale tanto paa navegadores como para NodeJS) y que sirve precisamente para eso.
Cómo descargar un archivo con una URI de tipo "data:"
Vale, ahora que ya sabemos cómo "crear" archivos en el navegador simulando URLs como los que acabo de explicar, vamos a ver qué más necesitamos.
Aparte de codificar adecuadamente cada formato y montar el URI como acabo de enseñar, lo único que necesitamos para poder hacer la descarga es que el usuario pulse algún enlace o botón para poder provocar la descarga. No serviría hacerlo solo por código (a partir de un evento o de un temporizador) ya que los navegadores anulan las acciones que no son provocadas por los usuarios y que pueden suponer un problema de seguridad.
Cuando el usuario pulse sobre el enlace en cuestión, para poder provocar la descarga lo que podemos hacer es lo siguiente:
- Creamos un enlace en memoria
- Le asignamos como
href el URI que hemos creado antes, así "navegará" a él cuando pulsemos.
- Asignamos en su propiedad
download el nombre que le queremos dar al archivo que pretendemos generar. Esta propiedad vale precisamente para esto, aunque no está soportada por Internet Explorer (más sobre esto luego).
- Simulamos una pulsación llamando al método
click del enlace. Esto funcionará porque este código lo estamos llamando desde una acción del usuario, y por lo tanto está provocado por él también y el navegador no lo bloquea.
Esto provocará la descarga del archivo con el nombre que queramos y el contenido construido en el punto anterior.
Nota: en Firefox si no metemos el enlace dentro del DOM y solo lo tenemos en memoria, la pulsación simulada no funciona. Por ello debemos hacer tres pasos extra (que servirán en los demás navegadores aunque no sean necesarios), a saber:
- Colocarle un estilo
diplay:none para que no se vea.
- Añadir el enlace al DOM.
- Simular la pulsación.
- Retirar el enlace del DOM para dejarlo como estaba.
Un poco lioso pero con esto funciona en todos los navegadores modernos (menos Edge).
Esto funciona en los navegadores modernos, pero no así en Internet Explorer. En este navegador antiguo, pero todavía muy utilizado por mucha gente, lo que debemos hacer es muy distinto y más lioso y nos complica la vida al tener que darle soporte, pero básicamente es:
- Crear un iframe en memoria.
- ocultarlo con
display:none;.
- Agregarlo al DOM.
- Inicializar el documento del iframe como si fuera a contener HTML, con
open.
- Escribir el contenido de nuestro archivo sin la cabecera del tipo MIME, ni
data: ni codificando nada: "a pelo", los datos "limpios".
- Cerrar el documento del
iframe y colocar el foco en éste.
- LLamar al método
execCommand.aspx) de Internet Explorer para pasarle el comando "SaveAs" y forzar el guardado del documento con el nombre que queramos.
- Retirar el
iframe, que ya no necesitamos, tras la descarga.
Buff!, un rollo, pero no queda más remedio. Con esto lograremos que funcione en IE incluso en versiones antiguas.
Lo que no he conseguido de ninguna manera es que funciona con Microsoft Edge. Este navegador va "a su bola" completamente. De hecho la técnica usada para los demás navegadores parece funcionar, pero no logro que salga el diálogo de descarga. Es decir, aunque la descarga parece que se inicia y no da ningún error, no aparece por ningún lado preguntando dónde quieres guardar el archivo, y cuando vas a cerrar el navegador te dice que hay descargas pendientes. Pero no paso de ahí por más vueltas que le he dado. Si se te ocurre cómo solucionarlo mándame un Pull Request en GitHub (ver más abajo)
Codificación de caracteres no-ingleses
Vale, ya tenemos todo más o menos planteado. Pero cuando vas a probarlo con datos que tienen eñes, tildes y cosas así (caracteres no-ingleses) verás que se ven mal en todos los archivos...
El motivo es que si no lo indicas explícitamente tanto Excel, como Word, etc... interpretan el archivo como ANSI aunque esté codificado como UTF-8, y por lo tanto trastoca la codificación, viéndose todos estos caracteres mal.
Para solucionar este problema hay que actuar de manera diferente según el formato de archivo.
En el caso de archivos que llevan HTML, como Excel, Word o el propio formato HTML basta con incluir, como parte del HTML que enviamos codificado, la siguiente cabecera que indica la codificación que se usa:
<meta charset="UTF-8">
Simplemente metiendo esto ya lo saben interpretar y se ve perfectamente.
En el caso de formatos textuales, como CSV, es más complicado porque no podemos meter ningún tipo de cabecera que puedan interpretar, y dependiendo del programa que uses para abrirlo, lo interpretará bien o no. Por ejemplo Excel interpreta de manera errónea los archivos .csv aunque estén en UTF-8 y se ven mal los caracteres no-ingleses. Para solucionarlo, lo que he hecho es forzar que se detecten los archivos como UTF-8 al abrirlos metiéndole delante los tres caracteres del Byte Order Mark o BOM.aspx).
Haciendo esto Excel los interpreta correctamente cuando los importamos desde el menú Datos·Desde texto y las tildes y demás se ven perfectamente.
Una biblioteca lista para utilizar
Lo anterior era la teoría. En la práctica he implementado todo esto en una biblioteca Open Source llamada exporter.js que puedes encontrar en GitHub lista para ser utilizada, también incluso minimizada (ocupa en este caso tan solo 2,17KB)
Esta biblioteca, al agregarla a una página, crea un objeto global llamado Exporter el cual cuenta con un método llamado export que sirve exportar cualquier elemento de la página que le pasemos a los formatos soportados, que son:
- Excel (.xls)
- CSV (.csv)
- Word (.doc)
- HTML (.html)
El método tiene eta firma:
Exporter.export(DOMElmt, fileName, dataName);
y toma como parámetros el elemento del DOM cuyo contenido completo queremos descargar en un archivo, el nombre del archivo y opcionalmente el nombre que le queremos dar a la hoja interior en caso de exportarlo a Excel.
Para determinar el tipo del archivo y por lo tanto formatearlo adecuadamente se utiliza la extensión de éste.
Por ejemplo, para descargar una tabla en formato Excel escribiríamos en el click de un enlace lo siguiente:
var datos = document.GetElementById('TablaDatos);
Exporter.export(datos, 'cursos.xls', 'Cursos')
y ya se lanzaría el diálogo para guardar la Excel a disco con el nombre indicado.
Si quisiésemos un archivo de Word, sería casi igual, pero sin el último parámetro:
var datos = document.GetElementById('TablaDatos);
Exporter.export(datos, 'cursos.doc')
Fíjate que en el caso de Excel o CSV el elemento debe ser una tabla o lanzará una excepción o para indicarlo, ya que se trata de formatos tabulares. En el caso de Word o HTML puede ser cualquier elemento o incluso la página completa si quisiésemos, y funcionará sin problemas.
En el caso de CSV he implementado un método para recorrer la tala por filas y celdas y generar los datos en el formato delimitado por comas.
En Github tienes el código fuente completo con un montón de comentarios (aunque en inglés, es lo que hay: hace tiempo que decidí que todos los proyectos Open Source lo hago en este idioma). Si quieres puedes echarle un vistazo para entender mejor todo lo que he explicado antes, y las dificultades que hay.
Tienes un archivo .html de prueba con una tabla (de cursos) y enlaces para descargarla en todos los formatos.
Aunque esta exportación a Excel y Word funciona perfectamente, debemos saber que no es el formato nativo de estos programas, sino que es simple HTML por debajo.
En el caso de Word no hay diferencia en el sentido de que los abre sin "quejarse". Pero en el caso de Excel es más problemático porque al intentar abrir el archivo generado nos avisa con este mensaje:

Este mensaje lo que dice es que el formato del archivo (que es HTML en realidad) y la extensión no coinciden, y si queremos abrirlo. Basta con decir que sí y lo abre perfectamente, mostrando incluso las celdas con colores y formatos:
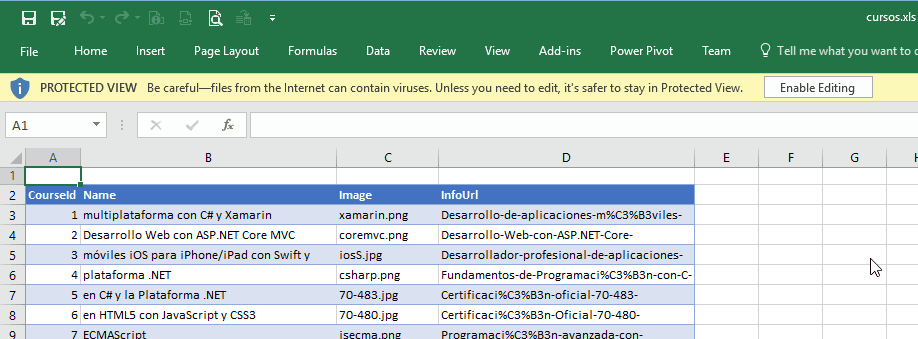
Por defecto, como todo archivo bajado de Internet, lo abre en modo de solo lectura, por seguridad.
El caso es que el formato de Excel o Word nativos (.xlsx o .docx) son formatos binarios que deben cumplir una serie de convenciones y normas. En realidad son archivos comprimidos con ZIP con una serie de archivos y carpetas dentro. Del mismo modo otros tipos de archivo habituales, como los PDF por ejemplo, son también archivos más complejos y binarios.
Es posible generarlos desde JavaScript puro, pero requieren muchas más cosas de las que he explicado aquí, y necesitan mucho más código y una enorme complejidad. Con la biblioteca que he creado y la explicación de este artículo podrás crear archivos sencillos como los mencionados, que pueden resultar muy útiles y demuestran la potencia de JavaScript y los navegadores modernos.
La creación de los otros tipos de archivos usan técnicas más avanzadas que, de momento, no tengo capacidad de explicar en el blog. Para que te hagas una idea, crear esta biblioteca de ejemplo y este artículo me ha llevado unas 8 horas. Lo otro me llevaría mucho más, así que no lo voy a hacer, sorry :-S
De todos modos espero que esta explicación y la biblioteca exporter.js te resulten útiles. Si quieres contribuir a la misma ampliando sus capacidades, te doy la bienvenida desde ahora mismo :-)
Y ya sabes, si quieres aprender JavaScript (y ECMAScript) a fondo conmigo para responder a todas tus dudas tienes este curso o mejor aún este otro curso que además explica a fondo jQuery, APIs de HTML5, y muchas otras cosas interesantes :-)
¡Saludos!