Las expresiones regulares son uno de los mejores inventos de la historia de la programación. Yo las uso para todo. En cuanto hay cualquier cadena de texto involucrada, raro es que no ahorre mucho tiempo usando expresiones regulares, sobre todo en editores de código, pero también en muchos de mis propios programas.
El problema de las expresiones regulares es que, aunque lo básico es sencillo, pueden llegar a ser muy fastidiadas. Hay algunas que, para calcularlas, de entrada pueden parecer muy simples pero que te puede llevar horas dar con ellas. Son casi un lenguaje de programación en si mismas 😊
Otra cosa que hay que saber es que Internet está lleno de páginas con información equivocada o directamente errónea sobre expresiones regulares. Por ejemplo, hace una temporada una alumna de mi curso de JavaScript en campusMVP me preguntaba esto:
Estoy practicando las expresiones regulares, y no soy capaz de hacer una expresión que dada una cadena muestre coincidencia cuando no tenga más de tres "a" o tres "b" seguidas.
La cadena es:
a
aba
aabb
aabbb
aaabbb
aa
baa
abab
ababa
bababa
ab
bbb
baaa
abbba
bbaabb
ba
aaaa
baba
bbaab
bbabaa
aaa
aaba
bbbb
bbbaa
bbbabb
La solución que dan es ^[^aaaa]|[^bbbb]$^[^bbbb]|[^aaaa]$, pero lo pruebo y no me funciona. ¿Es correcta la expresión o estoy haciendo algo mal?
Este es el caso con la solución que le daban para este problema: no solo es errónea sino que además, aunque funcionase, no es muy eficiente ni concisa.
Si analizamos esta expresión regular que le daban:
^[^aaaa]|[^bbbb]$^[^bbbb]|[^aaaa]$
lo que significa es:
^: Comienzo de línea (o texto, si no la haces multi-línea, cosa que debieras en este caso)- Cualquier caracter que NO sea uno de este conjunto
[aaaa], o sea, "a", ya que un conjunto formado por varias veces la misma letra es realmente solo esa letra. Es decir, [aaaa] no equivale a 4 "aes" seguidas, sino a una sola "a". Si quieres 4 aes seguidas deberías usar paréntesis, no corchetes: (aaaa) pero entonces el ^ no lo puedes poner dentro. Claramente vamos mal ya desde el inicio.
- Lo mismo con la "b", y con el "|", que quiere decir uno u otro. Es decir, hasta aquí llevamos una cadena que NO empiece por "a" o por "b", que es lo mismo que escribir esto:
^[^ab].
- Luego hay un
$, o sea, fin de línea. Cualquier cosa que pongas después no tiene sentido, puesto que ya estás marcando el fin de línea. Y luego repite lo mismo pero del revés...
Esto no tiene mucho sentido.
De hecho si la comprobamos con esta estupenda herramienta que te da una visualización gráfica de expresiones regulares, verás que toda expresión lo que significa es esto:
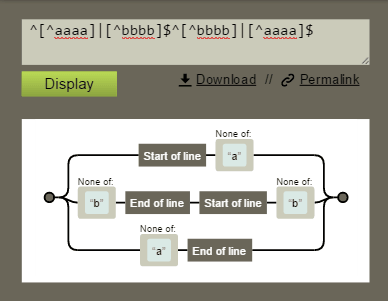
o sea, una cadena que no empiece ni termine por a o por b y que no lleve por el medio, en este orden, una b, un fin de línea, un comienzo de linea y una b... WTF?
Como vemos no tiene mucho sentido.
La forma de abordar este caso concreto es completamente diferente.
En primer lugar deberíamos tratar de determinar el caso positivo, es decir, cómo obtener líneas que contengan al menos 3 aes o tres bes seguidas. De entrada podríamos pensar en esto: [ab][ab][ab]. Pero no está bien ya que esto es una a o b, una a o b, una a o b seguidas, lo cual encaja con "aaa" y "bbb", pero también con "aba" o "aab", etc... que no es lo que buscamos.
Aquí es donde entran en juego las referencias hacia atrás o backreferences. Éstas nos permiten referirte a capturas anteriores y son indispensables para hacer cosas como esta. En este caso tendríamos que capturar el caracter o caracterers que nos interesen (o sea, "a" o "b"), y luego refererirnos a esta captura con una expresión del tipo "\x", donde la "x" es el número de la captura que nos interesa, o sea: dentro de todas las partes de una cadena que se capturen (que vayan entre paréntesis), la posición que nos interese.
En este caso solo capturamos la letra "a" o la "b", por lo que la expresión es muy sencilla:
([ab])\1\1
que significa que se capturará la primera letra "a" o "b" que se encuentre y luego dos veces seguidas más esa misma letra:
![Representación visual de la expresión regular ([ab])\1\1](/Blog/image.axd?picture=/2019/regexp-letrasrepe/exprreg-01.png)
o bien también nos vale:
([ab])\1{2,}
que significa que se repetirá la captura de la primera letra "a" o "b" al menos 3 veces, pero podrían ser más (de ahí el {2,}):
![Representación visual de la expresión regular ([ab])\1{2,}](/Blog/image.axd?picture=/2019/regexp-letrasrepe/exprreg-02.png)
Con esto ya tenemos mucho camino andado.
Ahora nos interesa averiguar qué líneas de nuestro texto NO contienen este patrón.
Para hacer esto necesitamos usar una búsqueda anticipada negativa, es decir, (?! PATRON), pero no podemos buscar solamente el patrón anterior, ya que ese patrón tiene que formar parte de algo más. Ser parte de una línea. Si lo ponemos así:
(?!([ab])\1\1)
nos encontrará solamente cadenas vacías, pues ninguna frase del ejemplo cumple que simplemente no tenga ese patrón (tienen más cosas, otras letras). Todo esto lo podemos ir comprobando con https://regex101.com/, que además nos explica a la derecha exactamente qué hace la expresión regular (la verdad es que hay herramientas alucinantes por ahí, y encima gratuitas).
Vale, entonces lo que tenemos que hacer es asegurarnos de que estamos hablando de una línea que contenga algo más, por lo que lo único que tenemos que hacer es ponerle un cuantificador de "cualquier cosa", o sea, esto delante: .*? (la ? es para que no sea "ambicioso" o expansivo, en inglés "greedy"):
(?!.*?([ab])\1\1)
Pero tampoco nos llega porque esto sigue siendo una expresión sin captura: es decir, que no captura el resultado que nos interesa. Es importante recordar que las expresiones de tipo (? ) no capturan nada, solo sirven para ver si hay ciertos patrones. Así que tenemos que meter algo fuera de ésta, en este caso es algo tan sencillo como:
^(?!.*?([ab])\1\1).+
que indica que es una línea (^, comienzo de línea), que no puede contener 3 aes o 3 bes seguidas y que puede contener cualquier otra cosa (pero debe contener "algo", sino nos daría también líneas vacías y cadenas vacías), o sea .+.
Con esto tenemos la expresión que buscábamos.
Si la examinamos con RegExpr:
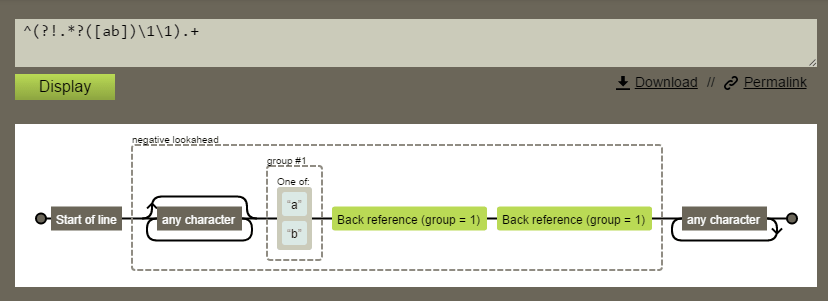
Esta expresión hace precisamente lo que queríamos.
Para ser concretos, en JavaScript esta expresión se escribiría así:
/^(?!.*?([ab])\1\1).+/mg
para que sea búsqueda global (modificador g) y multi-línea (modificador m), que es lo que necesitamos en este caso.
Como vemos, de entrada no es tan fácil ni tan intuitiva como podría parecer. Y una expresión tan aparentemente sencilla como esta te puede llevar un buen rato dar con ella.
Las expresiones regulares no son nada fáciles, y de hecho la única forma de aprender a hacerlas es practicar, practicar y practicar. Eso sí, una vez que las dominas te valen para cualquier lenguaje de programación, para trabajar fuera de programación (por ejemplo para búsquedas y sustituciones en editores de texto avanzados), y te dan una potencia increíble. No muchos programadores llegan a dominarlas porque son aburridas y hace falta practicar mucho para lograrlo pero, en mi opinión, el que las domina sobresale mucho frente a los demás.
¡Espero que te resulte útil!